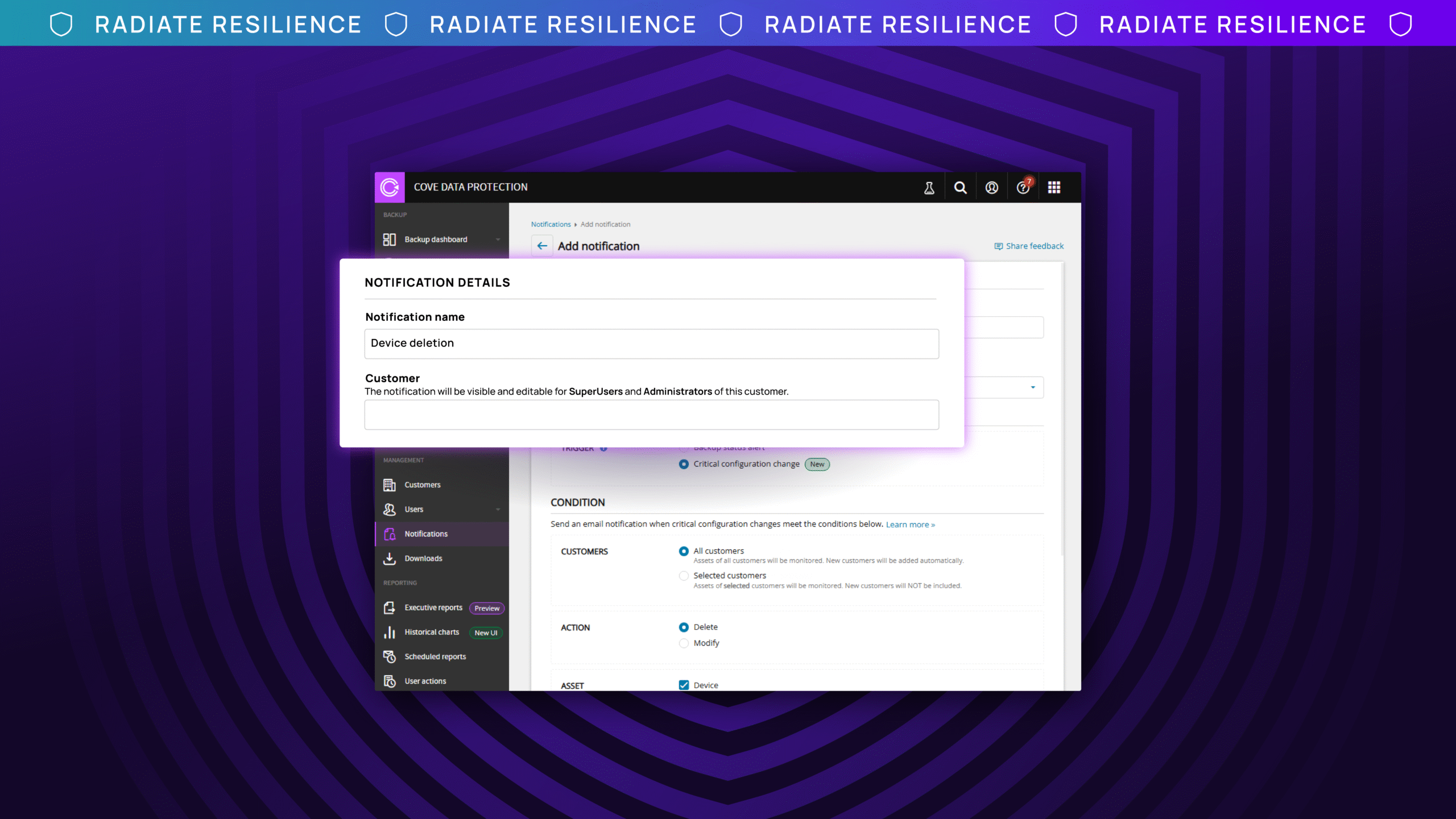
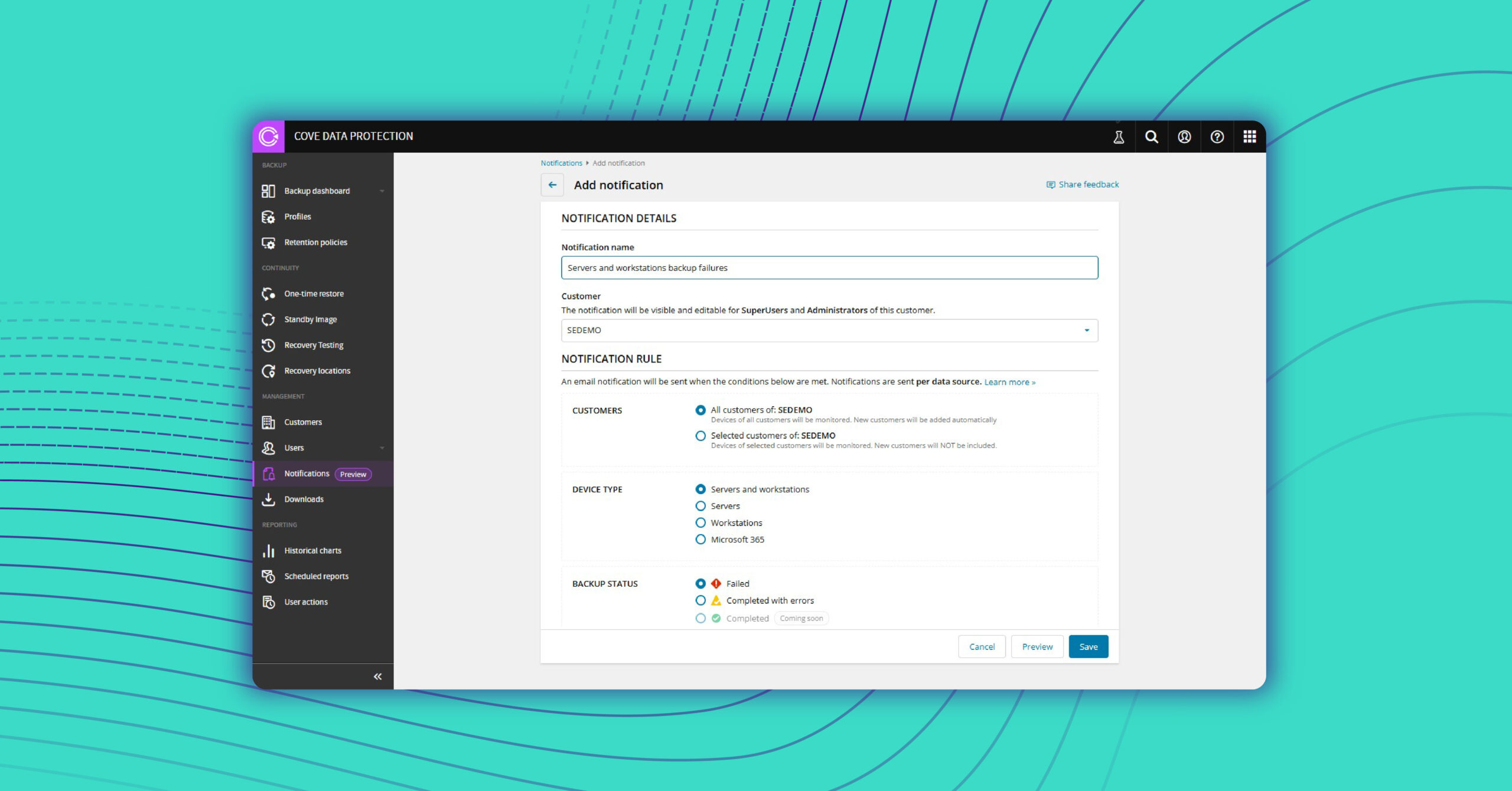
N-able is recognized in the Gartner® Magic Quadrant™ for Endpoint Management Tools
January 14th, 2026
5 min read
By N‑able
2026 SOC Report Insights: see how attacks are shifting and where modern SOCs are struggling to keep up.
Get the latest tips, news, and insights on everything from using N‑able products to responding to industry trends along with advice for growing your business.
By N‑able
By N‑able
April 28th, 2026 5 min read
By N‑able
April 28th, 2026 10 min read
By N‑able
April 27th, 2026 12 min read
By N‑able
April 22nd, 2026 7 min read

By Oliver Bengtsson
April 21st, 2026 4 min read
By N‑able
April 17th, 2026 14 min read
By N‑able
April 16th, 2026 12 min read
By N‑able
April 15th, 2026 15 min read
By N‑able
April 14th, 2026 12 min read
By N‑able
April 13th, 2026 5 min read
By N‑able
April 13th, 2026 13 min read
By N‑able
April 12th, 2026 12 min read
By N‑able
April 11th, 2026 13 min read
By N‑able
April 10th, 2026 13 min read
By Oliver Bengtsson
April 9th, 2026 4 min read
By N‑able
April 9th, 2026 12 min read
By N‑able
April 8th, 2026 14 min read
By N‑able
April 6th, 2026 6 min read
By N‑able
March 30th, 2026 5 min read
By N‑able
March 29th, 2026 13 min read
By N‑able
March 28th, 2026 11 min read
By N‑able
March 27th, 2026 12 min read
By N‑able
March 26th, 2026 11 min read
By N‑able
March 25th, 2026 12 min read
By N‑able
March 24th, 2026 14 min read
By N‑able
March 21st, 2026 13 min read
By N‑able
March 20th, 2026 14 min read

By Ash Luitel
March 19th, 2026 4 min read
By N‑able
March 19th, 2026 13 min read
By N‑able
March 18th, 2026 10 min read
By Ash Luitel
March 17th, 2026 5 min read
By N‑able
March 15th, 2026 11 min read
By N‑able
March 14th, 2026 14 min read
By N‑able
March 13th, 2026 13 min read
By N‑able
March 12th, 2026 10 min read
By N‑able
March 11th, 2026 12 min read
By N‑able
March 10th, 2026 11 min read
By N‑able
March 9th, 2026 10 min read
By N‑able
March 8th, 2026 13 min read
By N‑able
March 7th, 2026 12 min read
By N‑able
March 6th, 2026 11 min read
By N‑able
March 5th, 2026 11 min read
By N‑able
March 4th, 2026 12 min read
By N‑able
March 3rd, 2026 13 min read
By N‑able
March 2nd, 2026 11 min read
By N‑able
March 1st, 2026 13 min read
By N‑able
February 28th, 2026 9 min read
By N‑able
February 27th, 2026 10 min read
By N‑able
February 26th, 2026 13 min read

By Stefan Voss
February 25th, 2026 5 min read
By N‑able
February 25th, 2026 11 min read
By N‑able
February 24th, 2026 13 min read
By N‑able
February 23rd, 2026 14 min read
By N‑able
February 22nd, 2026 10 min read
By N‑able
February 21st, 2026 12 min read
By N‑able
February 19th, 2026 2 min read
By Emma Nistor
February 17th, 2026 6 min read
By Ash Luitel
February 17th, 2026 8 min read
By N‑able
February 16th, 2026 12 min read
By N‑able
February 15th, 2026 13 min read
By N‑able
February 14th, 2026 11 min read
By N‑able
February 13th, 2026 11 min read
By N‑able
February 12th, 2026 9 min read
By N‑able
February 11th, 2026 9 min read
By N‑able
February 10th, 2026 10 min read
By N‑able
February 9th, 2026 12 min read
By Ash Luitel
February 4th, 2026 7 min read
By N‑able
February 4th, 2026 3 min read

By Ovidiu Cobzaru
February 3rd, 2026 8 min read
By Ovidiu Cobzaru
February 1st, 2026 7 min read
By N‑able
January 30th, 2026 9 min read
By N‑able
January 29th, 2026 6 min read
By N‑able
January 29th, 2026 12 min read
By N‑able
January 28th, 2026 9 min read
By N‑able
January 24th, 2026 12 min read
By Oliver Bengtsson
January 23rd, 2026 3 min read
By Oliver Bengtsson
January 23rd, 2026 4 min read
By N‑able
January 23rd, 2026 13 min read
By N‑able
January 22nd, 2026 16 min read
By N‑able
January 21st, 2026 10 min read
By N‑able
January 20th, 2026 6 min read
By N‑able
January 20th, 2026 5 min read
By N‑able
January 20th, 2026 6 min read
By N‑able
January 20th, 2026 5 min read
By N‑able
January 20th, 2026 10 min read
By N‑able
January 18th, 2026 11 min read
By N‑able
January 17th, 2026 13 min read
By N‑able
January 15th, 2026 13 min read
By N‑able
January 14th, 2026 5 min read
By N‑able
January 13th, 2026 6 min read
By N‑able
January 13th, 2026 15 min read
By N‑able
January 8th, 2026 8 min read
By N‑able
December 31st, 2025 17 min read
By N‑able
December 29th, 2025 11 min read
By N‑able
December 23rd, 2025 11 min read
By N‑able
December 2nd, 2025 4 min read

By Paul Kelly
November 27th, 2025 6 min read

By Ben Lee
November 26th, 2025 7 min read

By Jim Waggoner
November 20th, 2025 5 min read
By Jim Waggoner
November 19th, 2025 5 min read
By N‑able
November 17th, 2025 4 min read
By Jim Waggoner
November 17th, 2025 4 min read
By Jim Waggoner
November 14th, 2025 5 min read

By Lewis Pope
November 13th, 2025 14 min read
By Jim Waggoner
November 12th, 2025 4 min read
By N‑able
November 12th, 2025 3 min read
By Oliver Bengtsson
November 11th, 2025 4 min read

By Pete Roythorne
November 10th, 2025 6 min read
By Lewis Pope
November 7th, 2025 11 min read

By Eric Harless
November 6th, 2025 8 min read
By Stefan Voss
November 4th, 2025 3 min read
By N‑able
October 30th, 2025 3 min read
By Paul Kelly
October 30th, 2025 4 min read
By Lewis Pope
October 29th, 2025 5 min read
By Ben Lee
October 28th, 2025 8 min read
By N‑able
October 23rd, 2025 3 min read
By Ben Lee
October 22nd, 2025 5 min read
By Paul Kelly
October 21st, 2025 4 min read
By Emma Nistor
October 20th, 2025 6 min read

By Joe Ferla
October 17th, 2025 8 min read
By Lewis Pope
October 16th, 2025 21 min read
By N‑able
October 14th, 2025 5 min read
By Lewis Pope
October 2nd, 2025 9 min read

By Stefanie Hammond
September 29th, 2025 11 min read
By Ovidiu Cobzaru
September 25th, 2025 7 min read
By Stefan Voss
September 24th, 2025 6 min read
By N‑able
September 18th, 2025 3 min read
By Paul Kelly
September 17th, 2025 6 min read
By Lewis Pope
September 16th, 2025 6 min read
By N‑able
September 11th, 2025 2 min read
By N‑able Guest
September 11th, 2025 12 min read
By Emma Nistor
September 10th, 2025 11 min read
By Lewis Pope
September 9th, 2025 8 min read
By N‑able
September 3rd, 2025 4 min read
By N‑able
September 2nd, 2025 3 min read
By Lewis Pope
August 20th, 2025 9 min read
By N‑able
August 18th, 2025 3 min read
By Lewis Pope
August 12th, 2025 10 min read
By Lewis Pope
August 11th, 2025 6 min read
By Lewis Pope
August 8th, 2025 9 min read
By Paul Kelly
August 6th, 2025 8 min read
By Stefanie Hammond
August 5th, 2025 8 min read
By Lewis Pope
August 5th, 2025 8 min read
By Lewis Pope
August 5th, 2025 9 min read
By Lewis Pope
August 4th, 2025 10 min read
By N‑able
July 31st, 2025 3 min read
By Emma Nistor
July 31st, 2025 9 min read
By Eugene Yamnitsky
July 30th, 2025 9 min read

By David Weeks
July 28th, 2025 7 min read
By N‑able
July 24th, 2025 3 min read

By Tracy Trottier
July 23rd, 2025 10 min read

By Jason Murphy
July 22nd, 2025 4 min read
By David Weeks
July 21st, 2025 7 min read
By N‑able
July 17th, 2025 2 min read
By N‑able Guest
July 17th, 2025 11 min read

By Nicole Reineke
July 15th, 2025 7 min read
By Ben Lee
July 10th, 2025 9 min read
By N‑able
July 10th, 2025 4 min read
By Lewis Pope
July 10th, 2025 22 min read
By N‑able
July 9th, 2025 6 min read
By N‑able
July 9th, 2025 9 min read
By Nicole Reineke
July 8th, 2025 7 min read
By N‑able
July 8th, 2025 11 min read
By Paul Kelly
July 4th, 2025 7 min read
By N‑able
July 3rd, 2025 1 min read
By Jim Waggoner
July 2nd, 2025 19 min read
By Stefanie Hammond
June 30th, 2025 15 min read
By N‑able Guest
June 26th, 2025 6 min read
By N‑able
June 26th, 2025 4 min read
By Paul Kelly
June 24th, 2025 7 min read
By Paul Kelly
June 23rd, 2025 6 min read
By N‑able
June 20th, 2025 3 min read
By Pete Roythorne
June 18th, 2025 6 min read

By Kyle Lawhorn
June 16th, 2025 6 min read
By N‑able
June 12th, 2025 5 min read
By N‑able
June 12th, 2025 5 min read
By Lewis Pope
June 12th, 2025 18 min read
By Tracy Trottier
June 11th, 2025 9 min read
By Pete Roythorne
June 10th, 2025 6 min read
By N‑able
June 4th, 2025 3 min read
By Pete Roythorne
June 4th, 2025 14 min read
By N‑able
June 3rd, 2025 6 min read
By N‑able
May 29th, 2025 4 min read
By N‑able
May 29th, 2025 7 min read
By Stefanie Hammond
May 28th, 2025 8 min read
By N‑able
May 22nd, 2025 3 min read
By Stefanie Hammond
May 22nd, 2025 7 min read
By N‑able Guest
May 21st, 2025 8 min read
By Lewis Pope
May 16th, 2025 13 min read
By N‑able
May 15th, 2025 4 min read
By Paul Kelly
May 14th, 2025 12 min read
By N‑able Guest
May 13th, 2025 8 min read
By N‑able
May 11th, 2025 7 min read
By N‑able
May 11th, 2025 7 min read
By N‑able
May 10th, 2025 9 min read
By N‑able
May 10th, 2025 8 min read
By N‑able
May 9th, 2025 4 min read
By N‑able
May 8th, 2025 6 min read
By N‑able
May 8th, 2025 9 min read
By Stefanie Hammond
May 8th, 2025 9 min read
By N‑able
May 7th, 2025 10 min read
By Eric Harless
May 7th, 2025 8 min read
By N‑able
May 6th, 2025 5 min read
By N‑able
May 6th, 2025 4 min read
By N‑able
May 5th, 2025 16 min read
By Lewis Pope
May 5th, 2025 3 min read
By N‑able
May 4th, 2025 7 min read
By N‑able
May 3rd, 2025 11 min read
By N‑able
May 2nd, 2025 11 min read
By Jay Pitzer
April 30th, 2025 7 min read
By Pete Roythorne
April 30th, 2025 8 min read
By N‑able
April 30th, 2025 4 min read
By Paul Kelly
April 29th, 2025 7 min read
By N‑able
April 24th, 2025 3 min read
By Stefanie Hammond
April 22nd, 2025 5 min read
By N‑able
April 21st, 2025 5 min read
By N‑able
April 16th, 2025 4 min read
By Lewis Pope
April 15th, 2025 7 min read
By Joe Kern
April 15th, 2025 2 min read
By N‑able
April 14th, 2025 3 min read
By N‑able
April 8th, 2025 4 min read
By Jim Waggoner
April 4th, 2025 5 min read
By Stefanie Hammond
April 3rd, 2025 8 min read
By Lewis Pope
April 2nd, 2025 6 min read
By Pete Roythorne
April 1st, 2025 10 min read
By N‑able
March 27th, 2025 6 min read
By N‑able
March 26th, 2025 9 min read
By N‑able
March 23rd, 2025 11 min read
By N‑able
March 22nd, 2025 9 min read
By N‑able
March 21st, 2025 11 min read
By Eric Harless
March 20th, 2025 5 min read
By N‑able
March 20th, 2025 9 min read
By N‑able
March 19th, 2025 9 min read
By N‑able
March 16th, 2025 12 min read
By N‑able
March 15th, 2025 9 min read
By N‑able
March 14th, 2025 9 min read
By N‑able
March 13th, 2025 4 min read
By Paul Kelly
March 12th, 2025 5 min read
By N‑able
March 10th, 2025 11 min read
By N‑able
March 9th, 2025 7 min read
By N‑able
March 8th, 2025 8 min read
By Lewis Pope
March 6th, 2025 5 min read
By N‑able
March 4th, 2025 8 min read
By N‑able
February 27th, 2025 7 min read
By Pete Roythorne
February 27th, 2025 10 min read
By Lewis Pope
February 25th, 2025 9 min read
By Paul Kelly
February 23rd, 2025 6 min read
By N‑able Guest
February 19th, 2025 12 min read
By Jason Murphy
February 12th, 2025 4 min read
By Stefanie Hammond
February 11th, 2025 8 min read
By N‑able
February 7th, 2025 8 min read
By Pete Roythorne
February 5th, 2025 10 min read
By Ihor Pietukhov
February 4th, 2025 4 min read
By Lewis Pope
January 30th, 2025 4 min read
By Lewis Pope
January 30th, 2025 14 min read
By Pete Roythorne
January 29th, 2025 7 min read
By N‑able
January 24th, 2025 5 min read
By Pete Roythorne
January 23rd, 2025 7 min read
By Paul Kelly
January 21st, 2025 6 min read
By Pete Roythorne
January 16th, 2025 4 min read
By Paul Kelly
January 16th, 2025 9 min read
By Nicole Reineke
January 15th, 2025 4 min read
By Pete Roythorne
January 9th, 2025 10 min read
By N‑able Guest
January 9th, 2025 8 min read
By Stefanie Hammond
January 8th, 2025 8 min read
By N‑able
January 3rd, 2025 5 min read
By N‑able
December 20th, 2024 4 min read
By Lewis Pope
December 16th, 2024 12 min read
By Pete Roythorne
December 12th, 2024 3 min read
By Pete Roythorne
December 11th, 2024 6 min read
By N‑able
December 5th, 2024 7 min read
By N‑able
December 5th, 2024 2 min read
By Pete Roythorne
December 5th, 2024 6 min read
By Joe Kern
December 4th, 2024 7 min read
By Pete Roythorne
December 3rd, 2024 2 min read
By N‑able
November 21st, 2024 2 min read
By Paul Kelly
November 21st, 2024 7 min read
By Stefanie Hammond
November 20th, 2024 12 min read
By Tracy Trottier
November 19th, 2024 5 min read

By Chris Groot
November 19th, 2024 4 min read
By Lewis Pope
November 15th, 2024 6 min read
By N‑able
November 14th, 2024 3 min read
By Tracy Trottier
November 14th, 2024 6 min read
By Pete Roythorne
November 13th, 2024 7 min read
By N‑able
November 7th, 2024 7 min read
By Pete Roythorne
November 7th, 2024 8 min read
By N‑able
November 6th, 2024 3 min read
By Pete Roythorne
November 5th, 2024 7 min read
By Pete Roythorne
October 30th, 2024 10 min read
By Paul Kelly
October 29th, 2024 6 min read
By N‑able
October 29th, 2024 3 min read
By N‑able
October 28th, 2024 3 min read
By N‑able
October 24th, 2024 9 min read
By N‑able
October 21st, 2024 6 min read
By Pete Roythorne
October 17th, 2024 4 min read
By Lewis Pope
October 16th, 2024 7 min read
By Jason Murphy
October 15th, 2024 6 min read
By Pete Roythorne
October 14th, 2024 6 min read
By Lewis Pope
October 11th, 2024 10 min read
By Pete Roythorne
October 10th, 2024 5 min read
By N‑able
October 10th, 2024 2 min read
By Stefanie Hammond
October 10th, 2024 7 min read
By Pete Roythorne
October 9th, 2024 7 min read
By Paul Kelly
October 3rd, 2024 7 min read
By Pete Roythorne
October 2nd, 2024 6 min read
By Stefanie Hammond
October 1st, 2024 10 min read
By N‑able
September 26th, 2024 6 min read
By Pete Roythorne
September 25th, 2024 12 min read
By N‑able
September 19th, 2024 4 min read
By Lewis Pope
September 12th, 2024 20 min read
By N‑able
September 10th, 2024 4 min read
By Jason Murphy
September 9th, 2024 12 min read
By N‑able
September 5th, 2024 6 min read
By Pete Roythorne
September 5th, 2024 2 min read
By Pete Roythorne
September 4th, 2024 11 min read
By N‑able
August 30th, 2024 3 min read
By N‑able
August 29th, 2024 3 min read
By Paul Kelly
August 29th, 2024 11 min read
By N‑able
August 28th, 2024 12 min read
By Pete Roythorne
August 28th, 2024 12 min read
By N‑able
August 27th, 2024 7 min read
By N‑able
August 22nd, 2024 3 min read
By Stefanie Hammond
August 21st, 2024 13 min read
By Tracy Trottier
August 20th, 2024 11 min read
By N‑able
August 15th, 2024 3 min read
By Lewis Pope
August 15th, 2024 21 min read
By Tracy Trottier
August 14th, 2024 7 min read
By N‑able
August 13th, 2024 2 min read
By N‑able
August 1st, 2024 5 min read
By N‑able
August 1st, 2024 3 min read
By Paul Kelly
July 30th, 2024 6 min read
By N‑able
July 25th, 2024 11 min read
By Pete Roythorne
July 24th, 2024 3 min read
By N‑able
July 18th, 2024 7 min read
By N‑able
July 18th, 2024 3 min read
By Stefanie Hammond
July 17th, 2024 9 min read
By N‑able
July 11th, 2024 3 min read
By Pete Roythorne
July 11th, 2024 2 min read
By Tracy Trottier
July 11th, 2024 6 min read
By Lewis Pope
July 10th, 2024 17 min read
By N‑able
July 8th, 2024 2 min read
By N‑able
July 4th, 2024 3 min read
By N‑able
July 4th, 2024 15 min read
By Pete Roythorne
July 3rd, 2024 4 min read
By N‑able
July 2nd, 2024 4 min read
By N‑able
June 27th, 2024 8 min read
By N‑able Guest
June 25th, 2024 6 min read
By N‑able
June 20th, 2024 6 min read
By N‑able
June 20th, 2024 2 min read
By Paul Kelly
June 19th, 2024 6 min read
By Pete Roythorne
June 18th, 2024 5 min read
By N‑able
June 13th, 2024 10 min read
By Pete Roythorne
June 13th, 2024 3 min read
By Pete Roythorne
June 13th, 2024 4 min read
By Jason Murphy
June 13th, 2024 5 min read
By N‑able
June 6th, 2024 4 min read
By N‑able
June 6th, 2024 2 min read
By Tracy Trottier
June 5th, 2024 5 min read
By Stefanie Hammond
June 4th, 2024 12 min read
By N‑able
May 30th, 2024 2 min read
By N‑able
May 29th, 2024 2 min read
By N‑able
May 24th, 2024 7 min read
By Sergey Shaminko
May 23rd, 2024 5 min read
By Paul Kelly
May 22nd, 2024 7 min read
By Pete Roythorne
May 21st, 2024 2 min read
By Lewis Pope
May 16th, 2024 13 min read
By Tracy Trottier
May 14th, 2024 8 min read
By Sergey Shaminko
May 13th, 2024 6 min read
By Jason Murphy
May 9th, 2024 4 min read
By N‑able
May 9th, 2024 2 min read
By Pete Roythorne
May 8th, 2024 12 min read
By Tracy Trottier
May 2nd, 2024 6 min read
By Laura Moise
May 2nd, 2024 6 min read
By Pete Roythorne
April 30th, 2024 1 min read
By N‑able
April 25th, 2024 6 min read
By Stefanie Hammond
April 25th, 2024 9 min read
By N‑able
April 24th, 2024 2 min read
By Paul Kelly
April 24th, 2024 6 min read
By N‑able
April 22nd, 2024 4 min read
By Lewis Pope
April 18th, 2024 14 min read
By Pete Roythorne
April 9th, 2024 5 min read
By Tracy Trottier
April 8th, 2024 8 min read
By N‑able
April 4th, 2024 3 min read
By Stefanie Hammond
April 3rd, 2024 13 min read
By Pete Roythorne
April 2nd, 2024 5 min read
By N‑able
March 26th, 2024 6 min read
By Paul Kelly
March 26th, 2024 7 min read
By Lewis Pope
March 25th, 2024 12 min read
By Joe Ferla
March 21st, 2024 6 min read
By N‑able
March 20th, 2024 7 min read
By Tracy Trottier
March 14th, 2024 6 min read

By Chris Massey
March 13th, 2024 5 min read

By Carrie Reber
March 11th, 2024 3 min read
By N‑able
March 7th, 2024 3 min read
By Paul Kelly
March 6th, 2024 6 min read
By Pete Roythorne
March 5th, 2024 11 min read
By Pete Roythorne
February 29th, 2024 4 min read
By Pete Roythorne
February 28th, 2024 9 min read
By Pete Roythorne
February 27th, 2024 10 min read
By N‑able
February 22nd, 2024 2 min read
By N‑able
February 21st, 2024 5 min read
By Stefanie Hammond
February 20th, 2024 11 min read
By Lewis Pope
February 15th, 2024 13 min read
By Tracy Trottier
February 14th, 2024 7 min read
By N‑able
February 13th, 2024 4 min read
By N‑able
February 8th, 2024 6 min read
By N‑able
February 7th, 2024 2 min read
By Tracy Trottier
January 31st, 2024 7 min read
By Pete Roythorne
January 31st, 2024 4 min read
By Paul Kelly
January 30th, 2024 9 min read
By Pete Roythorne
January 19th, 2024 2 min read
By Stefanie Hammond
January 18th, 2024 8 min read
By N‑able
January 18th, 2024 6 min read
By Paul Kelly
January 11th, 2024 7 min read
By Lewis Pope
January 11th, 2024 11 min read
By Chris Massey
January 4th, 2024 9 min read
By N‑able
January 4th, 2024 7 min read
By N‑able
December 23rd, 2023 2 min read
By Lewis Pope
December 17th, 2023 13 min read
By Paul Kelly
December 15th, 2023 8 min read
By Chris Massey
December 14th, 2023 19 min read
By Stefanie Hammond
December 7th, 2023 9 min read
By N‑able
December 6th, 2023 2 min read
By Pete Roythorne
December 5th, 2023 6 min read
By Tracy Trottier
November 30th, 2023 7 min read
By Pete Roythorne
November 27th, 2023 4 min read
By Pete Roythorne
November 22nd, 2023 8 min read
By N‑able
November 21st, 2023 12 min read
By Tracy Trottier
November 21st, 2023 8 min read
By Lewis Pope
November 20th, 2023 15 min read
By Paul Kelly
November 16th, 2023 8 min read
By Stefanie Hammond
November 15th, 2023 9 min read
By N‑able
November 9th, 2023 2 min read
By Pete Roythorne
November 8th, 2023 5 min read
By Tracy Trottier
November 7th, 2023 7 min read
By Pete Roythorne
November 2nd, 2023 6 min read
By N‑able
November 1st, 2023 4 min read
By N‑able
October 26th, 2023 2 min read
By Pete Roythorne
October 25th, 2023 12 min read
By Jason Murphy
October 25th, 2023 8 min read
By Stefanie Hammond
October 19th, 2023 8 min read
By Pete Roythorne
October 17th, 2023 6 min read
By Tracy Trottier
October 12th, 2023 8 min read
By N‑able
October 12th, 2023 2 min read
By Lewis Pope
October 11th, 2023 23 min read
By Paul Kelly
October 5th, 2023 7 min read
By N‑able
October 3rd, 2023 2 min read

By Robert Wilburn
September 28th, 2023 6 min read
By Pete Roythorne
September 27th, 2023 6 min read
By David Weeks
September 21st, 2023 7 min read
By Pete Roythorne
September 19th, 2023 8 min read
By N‑able
September 14th, 2023 2 min read
By Lewis Pope
September 13th, 2023 16 min read
By Paul Kelly
September 12th, 2023 6 min read
By N‑able
September 7th, 2023 9 min read
By Emma Nistor
September 7th, 2023 6 min read
By Stefanie Hammond
September 5th, 2023 10 min read
By N‑able
August 31st, 2023 3 min read
By Trey West
August 31st, 2023 3 min read
By N‑able
August 29th, 2023 4 min read
By N‑able
August 28th, 2023 6 min read
By N‑able
August 24th, 2023 2 min read

By Marc-Andre Tanguay
August 24th, 2023 14 min read
By N‑able
August 22nd, 2023 5 min read
By Pete Roythorne
August 16th, 2023 6 min read
By N‑able
August 15th, 2023 2 min read
By Lewis Pope
August 14th, 2023 14 min read
By Jason Murphy
August 10th, 2023 6 min read
By N‑able Guest
August 9th, 2023 7 min read
By Pete Roythorne
August 7th, 2023 11 min read
By Paul Kelly
August 2nd, 2023 8 min read
By Stefanie Hammond
August 1st, 2023 12 min read

By Marilena Levy
July 28th, 2023 4 min read
By N‑able
July 27th, 2023 2 min read
By Pete Roythorne
July 25th, 2023 7 min read
By N‑able
July 21st, 2023 3 min read
By Pete Roythorne
July 19th, 2023 8 min read
By Pete Roythorne
July 18th, 2023 12 min read
By N‑able
July 18th, 2023 2 min read
By Lewis Pope
July 17th, 2023 16 min read
By Robert Wilburn
July 12th, 2023 6 min read
By Stefanie Hammond
July 11th, 2023 10 min read
By Pete Roythorne
July 6th, 2023 12 min read
By Jason Murphy
July 5th, 2023 12 min read
By Pete Roythorne
June 29th, 2023 6 min read
By N‑able
June 28th, 2023 3 min read
By N‑able
June 26th, 2023 2 min read
By Paul Kelly
June 22nd, 2023 9 min read
By N‑able
June 19th, 2023 2 min read
By Joe Ferla
June 15th, 2023 8 min read
By N‑able
June 14th, 2023 2 min read
By Lewis Pope
June 14th, 2023 15 min read
By Carrie Reber
June 13th, 2023 4 min read
By N‑able
June 12th, 2023 2 min read
By N‑able
June 6th, 2023 10 min read
By Paul Kelly
June 1st, 2023 7 min read
By Pete Roythorne
May 31st, 2023 7 min read
By Paul Kelly
May 25th, 2023 11 min read
By Stefanie Hammond
May 24th, 2023 8 min read
By Joe Ferla
May 23rd, 2023 7 min read
By Dave MacKinnon
May 18th, 2023 6 min read
By David Weeks
May 17th, 2023 6 min read
By N‑able
May 11th, 2023 1 min read
By N‑able
May 11th, 2023 1 min read
By Lewis Pope
May 10th, 2023 17 min read
By Marilena Levy
May 4th, 2023 9 min read
By David Weeks
May 2nd, 2023 4 min read

By Laura DuBois
April 27th, 2023 4 min read
By Stefan Voss
April 21st, 2023 8 min read
By Paul Kelly
April 20th, 2023 6 min read
By Stefanie Hammond
April 13th, 2023 8 min read
By Lewis Pope
April 12th, 2023 16 min read
By David Weeks
April 11th, 2023 6 min read
By Carrie Reber
March 31st, 2023 4 min read
By Marc-Andre Tanguay
March 30th, 2023 5 min read
By N‑able Guest
March 29th, 2023 9 min read
By Jason Murphy
March 23rd, 2023 2 min read
By Jason Murphy
March 23rd, 2023 6 min read
By N‑able
March 23rd, 2023 6 min read
By Paul Kelly
March 22nd, 2023 6 min read
By N‑able
March 21st, 2023 12 min read
By Pete Roythorne
March 15th, 2023 13 min read
By Dave MacKinnon
March 14th, 2023 8 min read
By N‑able
March 9th, 2023 7 min read
By Joe Ferla
March 9th, 2023 11 min read
By Aziree Pemberton
March 8th, 2023 6 min read
By N‑able
March 7th, 2023 6 min read
By Stefanie Hammond
March 1st, 2023 8 min read
By Chris Massey
February 28th, 2023 7 min read
By Chris Massey
February 23rd, 2023 7 min read
By Carrie Reber
February 21st, 2023 9 min read
By Lewis Pope
February 16th, 2023 14 min read
By Chris Massey
February 15th, 2023 8 min read
By Paul Kelly
February 9th, 2023 7 min read
By Emma Nistor
February 7th, 2023 9 min read
By Stefanie Hammond
February 2nd, 2023 9 min read
By Carrie Reber
February 1st, 2023 4 min read
By Aziree Pemberton
January 30th, 2023 9 min read
By Tracy Trottier
January 25th, 2023 8 min read
By Aziree Pemberton
January 19th, 2023 5 min read
By Stefanie Hammond
January 19th, 2023 9 min read
By Jason Murphy
January 12th, 2023 8 min read
By Paul Kelly
January 11th, 2023 7 min read
By Lewis Pope
January 10th, 2023 15 min read
By Brian Best
January 5th, 2023 5 min read
By Joe Ferla
January 3rd, 2023 5 min read
By Paul Kelly
December 21st, 2022 7 min read
By Stefanie Hammond
December 20th, 2022 6 min read
By Nicolae Tiganenco
December 15th, 2022 7 min read
By Lewis Pope
December 14th, 2022 14 min read
By Paul Kelly
December 13th, 2022 7 min read
By Marc-Andre Tanguay
December 8th, 2022 6 min read
By Paul Kelly
December 6th, 2022 8 min read
By N‑able
December 1st, 2022 10 min read
By Stefanie Hammond
December 1st, 2022 13 min read
By Brian Best
November 30th, 2022 6 min read
By Jason Murphy
November 29th, 2022 11 min read
By Aziree Pemberton
November 28th, 2022 5 min read
By Jason Murphy
November 17th, 2022 6 min read
By Stefan Voss
November 17th, 2022 8 min read
By Lewis Pope
November 15th, 2022 15 min read
By Paul Kelly
November 14th, 2022 6 min read
By Joe Kern
November 10th, 2022 11 min read
By Ian Waters
November 7th, 2022 9 min read
By Brian Best
November 3rd, 2022 10 min read
By Paul Kelly
November 2nd, 2022 9 min read
By Joe Ferla
November 1st, 2022 7 min read
By Stefanie Hammond
October 25th, 2022 10 min read
By Laura Moise
October 24th, 2022 5 min read
By Laura Moise
October 20th, 2022 4 min read
By Laura Moise
October 19th, 2022 6 min read
By Lewis Pope
October 17th, 2022 20 min read
By Carrie Reber
October 16th, 2022 5 min read
By Stefanie Hammond
October 13th, 2022 7 min read
By Joe Ferla
October 11th, 2022 7 min read
By Laura Moise
October 10th, 2022 5 min read
By David Weeks
October 6th, 2022 5 min read
By Laura Moise
October 5th, 2022 6 min read
By David Weeks
October 5th, 2022 10 min read
By Dave MacKinnon
October 4th, 2022 8 min read

By John Pagliuca
October 4th, 2022 5 min read
By Laura Moise
October 3rd, 2022 7 min read
By N‑able
September 30th, 2022 12 min read
By Paul Kelly
September 29th, 2022 8 min read
By Stefanie Hammond
September 27th, 2022 7 min read
By N‑able
September 22nd, 2022 8 min read
By Paul Kelly
September 20th, 2022 6 min read
By Lewis Pope
September 15th, 2022 13 min read
By Laura Moise
September 14th, 2022 8 min read
By Lewis Pope
September 14th, 2022 13 min read
By Joe Ferla
September 9th, 2022 10 min read

By Kathleen Pai
September 1st, 2022 7 min read
By Stefanie Hammond
August 31st, 2022 10 min read
By Paul Kelly
August 30th, 2022 8 min read
By N‑able
August 25th, 2022 3 min read
By N‑able
August 23rd, 2022 7 min read
By Paul Kelly
August 18th, 2022 6 min read
By N‑able
August 16th, 2022 2 min read
By N‑able
August 16th, 2022 9 min read
By N‑able
August 11th, 2022 6 min read
By Lewis Pope
August 10th, 2022 27 min read
By N‑able
August 10th, 2022 5 min read
By N‑able
August 9th, 2022 10 min read
By Stefanie Hammond
August 4th, 2022 11 min read
By Lewis Pope
August 3rd, 2022 11 min read
By Paul Kelly
August 2nd, 2022 7 min read
By N‑able
July 30th, 2022 6 min read
By Stefanie Hammond
July 28th, 2022 7 min read
By Davide Di Labio
July 27th, 2022 4 min read
By N‑able
July 26th, 2022 3 min read
By Emma Nistor
July 21st, 2022 6 min read
By N‑able
July 20th, 2022 5 min read
By Carrie Reber
July 19th, 2022 4 min read
By Lewis Pope
July 14th, 2022 9 min read
By Joe Kern
July 13th, 2022 13 min read
By Lewis Pope
July 12th, 2022 12 min read
By Marilena Levy
July 11th, 2022 5 min read
By Stefanie Hammond
July 7th, 2022 7 min read
By N‑able
July 6th, 2022 6 min read
By N‑able
July 4th, 2022 7 min read
By N‑able
June 30th, 2022 5 min read
By Stefanie Hammond
June 28th, 2022 7 min read
By Carrie Reber
June 27th, 2022 5 min read
By Laura Moise
June 24th, 2022 8 min read
By Paul Kelly
June 23rd, 2022 7 min read
By N‑able Guest
June 22nd, 2022 5 min read
By Laura Moise
June 21st, 2022 5 min read
By N‑able
June 21st, 2022 1 min read
By N‑able
June 21st, 2022 7 min read
By Carrie Reber
June 16th, 2022 6 min read
By Lewis Pope
June 14th, 2022 12 min read
By N‑able
June 8th, 2022 2 min read
By Stefanie Hammond
June 8th, 2022 10 min read
By Paul Kelly
June 1st, 2022 5 min read
By Marc-Andre Tanguay
May 26th, 2022 4 min read
By N‑able
May 24th, 2022 5 min read
By Stefanie Hammond
May 23rd, 2022 8 min read
By Davide Di Labio
May 19th, 2022 5 min read
By Lewis Pope
May 13th, 2022 13 min read
By N‑able
May 12th, 2022 7 min read
By Jason Murphy
May 11th, 2022 7 min read
By N‑able
May 5th, 2022 3 min read
By Marc-Andre Tanguay
May 4th, 2022 6 min read
By Stefanie Hammond
May 3rd, 2022 8 min read
By Marc-Andre Tanguay
April 26th, 2022 5 min read
By N‑able
April 25th, 2022 3 min read
By N‑able
April 22nd, 2022 11 min read
By Lewis Pope
April 21st, 2022 8 min read
By Stefanie Hammond
April 19th, 2022 6 min read
By Emma Nistor
April 18th, 2022 11 min read
By Marc-Andre Tanguay
April 14th, 2022 5 min read
By Lewis Pope
April 13th, 2022 15 min read
By Dave MacKinnon
April 12th, 2022 6 min read
By Davide Di Labio
April 8th, 2022 7 min read
By N‑able
April 6th, 2022 5 min read
By Eric Harless
March 31st, 2022 7 min read
By Stefanie Hammond
March 29th, 2022 7 min read
By Jason Murphy
March 24th, 2022 6 min read
By N‑able
March 22nd, 2022 5 min read
By Carrie Reber
March 21st, 2022 4 min read
By Stefanie Hammond
March 16th, 2022 6 min read
By N‑able
March 11th, 2022 10 min read
By Lewis Pope
March 10th, 2022 11 min read
By Kathleen Pai
March 8th, 2022 3 min read
By Stefanie Hammond
March 7th, 2022 9 min read
By N‑able Guest
March 2nd, 2022 5 min read
By Davide Di Labio
February 24th, 2022 5 min read
By Eric Harless
February 23rd, 2022 5 min read
By N‑able
February 17th, 2022 7 min read
By N‑able
February 16th, 2022 10 min read
By Marc-Andre Tanguay
February 15th, 2022 4 min read
By Eric Harless
February 10th, 2022 6 min read
By Lewis Pope
February 9th, 2022 10 min read
By Stefanie Hammond
February 8th, 2022 7 min read
By Lewis Pope
February 3rd, 2022 7 min read
By Stefanie Hammond
January 27th, 2022 7 min read
By N‑able
January 26th, 2022 6 min read
By N‑able Guest
January 26th, 2022 5 min read
By N‑able
January 24th, 2022 5 min read
By Marc-Andre Tanguay
January 20th, 2022 4 min read
By Stefanie Hammond
January 14th, 2022 7 min read
By Lewis Pope
January 13th, 2022 15 min read
By N‑able
January 6th, 2022 7 min read
By Marc-Andre Tanguay
January 5th, 2022 3 min read
By N‑able
December 29th, 2021 5 min read
By N‑able
December 28th, 2021 9 min read
By David Weeks
December 22nd, 2021 6 min read
By Stefanie Hammond
December 21st, 2021 5 min read
By Jason Murphy
December 20th, 2021 5 min read
By Dave MacKinnon
December 17th, 2021 8 min read
By Stefanie Hammond
December 16th, 2021 7 min read
By Lewis Pope
December 16th, 2021 7 min read
By N‑able Guest
December 13th, 2021 5 min read
By N‑able
December 7th, 2021 7 min read
By N‑able
December 2nd, 2021 5 min read
By N‑able
November 29th, 2021 6 min read
By Stefanie Hammond
November 24th, 2021 5 min read
By Tony Meyer
November 22nd, 2021 2 min read
By David Weeks
November 18th, 2021 5 min read
By Lewis Pope
November 10th, 2021 10 min read
By Stefanie Hammond
November 9th, 2021 7 min read
By Carrie Reber
November 3rd, 2021 3 min read
By N‑able Guest
October 28th, 2021 7 min read
By N‑able
October 27th, 2021 4 min read
By Dave MacKinnon
October 25th, 2021 3 min read
By David Weeks
October 22nd, 2021 6 min read
By Stefanie Hammond
October 21st, 2021 6 min read
By N‑able
October 21st, 2021 5 min read
By N‑able
October 20th, 2021 6 min read
By Dave MacKinnon
October 20th, 2021 4 min read
By Laura Moise
October 19th, 2021 9 min read
By Lewis Pope
October 13th, 2021 11 min read
By N‑able
October 12th, 2021 5 min read
By Stefanie Hammond
October 7th, 2021 5 min read
By Lewis Pope
October 6th, 2021 6 min read
By Jason Murphy
October 5th, 2021 4 min read
By Kathleen Pai
September 29th, 2021 7 min read
By N‑able Guest
September 28th, 2021 7 min read
By Stefanie Hammond
September 22nd, 2021 7 min read
By Carrie Reber
September 21st, 2021 4 min read
By N‑able
September 17th, 2021 5 min read
By David Weeks
September 17th, 2021 6 min read
By Lewis Pope
September 16th, 2021 12 min read
By N‑able Guest
September 15th, 2021 5 min read
By N‑able Guest
September 9th, 2021 6 min read
By Marc-Andre Tanguay
September 8th, 2021 6 min read
By Stefanie Hammond
September 7th, 2021 8 min read
By N‑able
September 2nd, 2021 7 min read
By Marc-Andre Tanguay
September 1st, 2021 6 min read
By Lewis Pope
August 31st, 2021 6 min read
By N‑able
August 26th, 2021 9 min read
By N‑able
August 19th, 2021 9 min read
By N‑able
August 18th, 2021 7 min read
By N‑able
August 18th, 2021 7 min read
By N‑able
August 18th, 2021 7 min read
By Stefanie Hammond
August 17th, 2021 7 min read
By Lewis Pope
August 11th, 2021 10 min read
By David Weeks
August 11th, 2021 6 min read
By Lewis Pope
August 6th, 2021 6 min read
By Stefanie Hammond
August 6th, 2021 7 min read
By Marc-Andre Tanguay
August 5th, 2021 3 min read
By N‑able
August 3rd, 2021 8 min read
By David Weeks
July 27th, 2021 6 min read
By Marc-Andre Tanguay
July 26th, 2021 3 min read
By Lewis Pope
July 23rd, 2021 3 min read
By Jason Murphy
July 22nd, 2021 5 min read
By N‑able
July 22nd, 2021 10 min read
By Marc-Andre Tanguay
July 21st, 2021 3 min read
By David Weeks
July 20th, 2021 4 min read
By N‑able
July 19th, 2021 6 min read
By Jason Murphy
July 16th, 2021 5 min read
By Lewis Pope
July 14th, 2021 6 min read
By Jason Murphy
July 13th, 2021 5 min read
By Tyler McDonald
July 13th, 2021 3 min read
By Stefanie Hammond
July 12th, 2021 8 min read
By N‑able
July 9th, 2021 5 min read
By Jason Murphy
July 8th, 2021 5 min read
By N‑able
July 7th, 2021 4 min read
By Lewis Pope
July 6th, 2021 9 min read
By Carrie Reber
July 1st, 2021 3 min read
By Stefanie Hammond
June 30th, 2021 7 min read
By N‑able
June 29th, 2021 9 min read
By Marc-Andre Tanguay
June 24th, 2021 5 min read
By Chris Groot
June 23rd, 2021 7 min read
By N‑able
June 22nd, 2021 7 min read
By David Weeks
June 19th, 2021 8 min read
By N‑able
June 11th, 2021 5 min read
By N‑able
June 10th, 2021 4 min read
By Lewis Pope
June 10th, 2021 6 min read
By N‑able
June 9th, 2021 4 min read
By N‑able
June 8th, 2021 5 min read
By N‑able
June 7th, 2021 4 min read
By Laura Moise
June 3rd, 2021 7 min read
By N‑able
June 2nd, 2021 9 min read
By N‑able
June 1st, 2021 5 min read
By Lewis Pope
May 25th, 2021 5 min read
By Jason Murphy
May 24th, 2021 5 min read
By Stefanie Hammond
May 21st, 2021 7 min read
By N‑able
May 18th, 2021 7 min read
By N‑able
May 18th, 2021 8 min read
By Lewis Pope
May 13th, 2021 8 min read
By N‑able
May 12th, 2021 9 min read
By N‑able
May 10th, 2021 8 min read
By N‑able
May 10th, 2021 7 min read
By Stefanie Hammond
May 7th, 2021 5 min read
By Eric Harless
May 6th, 2021 5 min read
By N‑able
May 4th, 2021 7 min read
By N‑able
May 4th, 2021 9 min read
By Jay Pitzer
April 30th, 2021 5 min read
By Pete Roythorne
April 29th, 2021 4 min read
By N‑able
April 26th, 2021 6 min read
By Jason Murphy
April 21st, 2021 4 min read
By Stefanie Hammond
April 21st, 2021 6 min read
By Marc-Andre Tanguay
April 20th, 2021 3 min read
By N‑able
April 19th, 2021 8 min read
By Lewis Pope
April 15th, 2021 22 min read
By Eric Harless
April 14th, 2021 4 min read
By N‑able
April 13th, 2021 5 min read
By N‑able
April 12th, 2021 9 min read
By Lewis Pope
April 8th, 2021 3 min read
By Jason Murphy
April 7th, 2021 4 min read
By N‑able
April 6th, 2021 7 min read
By N‑able
April 5th, 2021 13 min read
By Jason Murphy
April 1st, 2021 6 min read
By N‑able
March 31st, 2021 6 min read
By N‑able
March 30th, 2021 5 min read
By N‑able
March 25th, 2021 6 min read
By N‑able
March 24th, 2021 9 min read
By N‑able
March 23rd, 2021 4 min read
By Eric Harless
March 18th, 2021 6 min read
By N‑able
March 16th, 2021 7 min read
By N‑able
March 15th, 2021 6 min read

By Gill Langston
March 12th, 2021 8 min read
By Lewis Pope
March 12th, 2021 5 min read
By N‑able
March 11th, 2021 6 min read
By N‑able
March 11th, 2021 9 min read
By N‑able
March 10th, 2021 9 min read
By N‑able
March 9th, 2021 9 min read
By N‑able
March 2nd, 2021 9 min read
By Jason Murphy
February 25th, 2021 6 min read
By N‑able
February 24th, 2021 6 min read
By Eric Harless
February 18th, 2021 6 min read
By N‑able
February 17th, 2021 8 min read
By Marc-Andre Tanguay
February 11th, 2021 3 min read
By N‑able
February 11th, 2021 7 min read
By Gill Langston
February 10th, 2021 7 min read
By Carrie Reber
February 9th, 2021 4 min read
By N‑able
February 4th, 2021 8 min read
By N‑able
February 3rd, 2021 7 min read
By N‑able
February 2nd, 2021 8 min read
By Michael Tschirret
February 1st, 2021 4 min read
By Marc-Andre Tanguay
January 28th, 2021 4 min read
By N‑able
January 27th, 2021 7 min read
By N‑able
January 27th, 2021 9 min read
By N‑able
January 26th, 2021 6 min read
By N‑able
January 25th, 2021 7 min read
By Carrie Reber
January 21st, 2021 3 min read
By N‑able
January 21st, 2021 5 min read
By N‑able
January 20th, 2021 8 min read
By N‑able
January 19th, 2021 6 min read
By N‑able
January 18th, 2021 7 min read
By Gill Langston
January 14th, 2021 6 min read
By Nick Blozan
January 13th, 2021 5 min read
By N‑able Guest
January 7th, 2021 5 min read
By N‑able
January 6th, 2021 7 min read
By Laura Moise
January 6th, 2021 5 min read
By Laura Moise
January 5th, 2021 4 min read
By Laura Moise
January 4th, 2021 3 min read
By N‑able
December 23rd, 2020 7 min read
By Evan Young
December 22nd, 2020 4 min read
By Gill Langston
December 10th, 2020 7 min read
By Marc-Andre Tanguay
December 10th, 2020 5 min read
By N‑able
December 8th, 2020 5 min read
By N‑able
December 7th, 2020 3 min read
By N‑able
December 3rd, 2020 8 min read
By N‑able Guest
December 3rd, 2020 6 min read
By N‑able
December 2nd, 2020 7 min read
By N‑able
December 1st, 2020 6 min read
By Marc-Andre Tanguay
November 26th, 2020 4 min read
By Gill Langston
November 26th, 2020 8 min read
By Marc-Andre Tanguay
November 26th, 2020 4 min read
By N‑able
November 25th, 2020 5 min read
By N‑able
November 24th, 2020 8 min read
By N‑able
November 24th, 2020 6 min read
By N‑able
November 23rd, 2020 4 min read
By N‑able
November 19th, 2020 9 min read
By N‑able
November 18th, 2020 8 min read
By N‑able
November 17th, 2020 8 min read
By N‑able
November 12th, 2020 2 min read
By Gill Langston
November 12th, 2020 8 min read
By Marc-Andre Tanguay
November 11th, 2020 3 min read
By N‑able
November 9th, 2020 7 min read
By Eric Anthony
November 6th, 2020 4 min read
By N‑able
November 5th, 2020 3 min read
By Gill Langston
November 4th, 2020 6 min read
By N‑able
November 3rd, 2020 6 min read
By N‑able
November 3rd, 2020 5 min read
By N‑able
November 2nd, 2020 6 min read
By Chris Kissel
October 29th, 2020 5 min read
By Marc-Andre Tanguay
October 29th, 2020 3 min read
By Gill Langston
October 28th, 2020 5 min read
By Eric Anthony
October 27th, 2020 4 min read
By N‑able
October 27th, 2020 6 min read
By Carrie Reber
October 22nd, 2020 7 min read
By N‑able
October 21st, 2020 6 min read
By N‑able
October 21st, 2020 6 min read
By N‑able
October 20th, 2020 6 min read
By N‑able
October 14th, 2020 9 min read
By Gill Langston
October 14th, 2020 9 min read
By N‑able
October 13th, 2020 6 min read
By N‑able
October 12th, 2020 6 min read
By N‑able
October 8th, 2020 10 min read
By N‑able
October 7th, 2020 9 min read
By N‑able
October 7th, 2020 6 min read
By N‑able
October 6th, 2020 5 min read
By N‑able
October 5th, 2020 10 min read
By N‑able
October 1st, 2020 7 min read
By N‑able
October 1st, 2020 5 min read
By Marc-Andre Tanguay
September 30th, 2020 3 min read
By N‑able
September 30th, 2020 7 min read
By N‑able
September 29th, 2020 7 min read
By N‑able
September 28th, 2020 9 min read
By Eric Anthony
September 24th, 2020 4 min read
By Carrie Reber
September 23rd, 2020 4 min read
By N‑able
September 23rd, 2020 8 min read
By N‑able
September 22nd, 2020 7 min read
By John Pagliuca
September 21st, 2020 4 min read
By Eric Harless
September 17th, 2020 9 min read
By Mia Thompson
September 17th, 2020 5 min read
By Marc-Andre Tanguay
September 16th, 2020 4 min read
By N‑able
September 15th, 2020 7 min read
By N‑able
September 14th, 2020 7 min read

By Tim Brown
September 10th, 2020 7 min read
By Gill Langston
September 9th, 2020 8 min read
By N‑able
September 9th, 2020 5 min read
By Eric Anthony
September 8th, 2020 6 min read
By N‑able
September 8th, 2020 7 min read
By N‑able
September 7th, 2020 8 min read
By N‑able
September 3rd, 2020 7 min read
By N‑able
September 3rd, 2020 6 min read
By N‑able
September 2nd, 2020 9 min read
By Eric Anthony
August 26th, 2020 5 min read
By N‑able Guest
August 25th, 2020 6 min read
By N‑able
August 25th, 2020 7 min read
By N‑able
August 24th, 2020 6 min read
By Carrie Reber
August 20th, 2020 3 min read
By N‑able
August 18th, 2020 7 min read
By N‑able
August 17th, 2020 6 min read
By N‑able
August 14th, 2020 1 min read
By Gill Langston
August 12th, 2020 9 min read
By Marc-Andre Tanguay
August 12th, 2020 4 min read
By Eric Anthony
August 12th, 2020 5 min read
By N‑able
August 10th, 2020 6 min read
By Eric Anthony
August 6th, 2020 3 min read
By N‑able
August 5th, 2020 7 min read
By N‑able
August 4th, 2020 7 min read
By N‑able
August 3rd, 2020 10 min read
By Marc-Andre Tanguay
July 29th, 2020 5 min read
By N‑able
July 28th, 2020 5 min read
By N‑able
July 28th, 2020 6 min read
By Marilena Levy
July 23rd, 2020 6 min read
By N‑able Guest
July 22nd, 2020 6 min read
By Eric Harless
July 21st, 2020 6 min read
By N‑able
July 21st, 2020 3 min read
By N‑able
July 20th, 2020 6 min read
By Marc-Andre Tanguay
July 16th, 2020 6 min read
By N‑able Guest
July 16th, 2020 6 min read
By Gill Langston
July 15th, 2020 9 min read
By Eric Anthony
July 15th, 2020 4 min read
By Gill Langston
July 14th, 2020 2 min read
By N‑able
July 14th, 2020 7 min read
By N‑able
July 13th, 2020 9 min read
By Carrie Reber
July 9th, 2020 4 min read
By Marc-Andre Tanguay
July 8th, 2020 6 min read
By N‑able
July 8th, 2020 7 min read
By Mia Thompson
July 7th, 2020 7 min read
By Eric Harless
July 7th, 2020 8 min read
By Marc-Andre Tanguay
July 2nd, 2020 5 min read
By Carrie Reber
June 30th, 2020 4 min read
By Eric Anthony
June 30th, 2020 5 min read
By Eric Anthony
June 25th, 2020 5 min read
By N‑able
June 24th, 2020 7 min read
By Gill Langston
June 18th, 2020 7 min read
By Jay Pitzer
June 17th, 2020 6 min read
By N‑able
June 16th, 2020 9 min read
By N‑able
June 15th, 2020 8 min read
By N‑able
June 11th, 2020 1 min read
By Eric Anthony
June 10th, 2020 1 min read
By Gill Langston
June 10th, 2020 10 min read
By Kim Cecchini
June 9th, 2020 6 min read
By N‑able
June 8th, 2020 9 min read
By N‑able
June 8th, 2020 5 min read
By N‑able
June 4th, 2020 6 min read
By N‑able
June 4th, 2020 1 min read
By Carrie Reber
June 2nd, 2020 4 min read
By N‑able
June 1st, 2020 7 min read
By N‑able
June 1st, 2020 5 min read
By N‑able
May 28th, 2020 1 min read
By Mia Thompson
May 28th, 2020 6 min read
By Marc-Andre Tanguay
May 27th, 2020 5 min read
By Marilena Levy
May 27th, 2020 5 min read
By Tim Brown
May 26th, 2020 5 min read
By N‑able
May 25th, 2020 9 min read
By N‑able
May 25th, 2020 5 min read
By Tim Brown
May 21st, 2020 6 min read
By N‑able
May 21st, 2020 1 min read
By Eric Anthony
May 20th, 2020 4 min read
By N‑able
May 20th, 2020 8 min read
By N‑able
May 19th, 2020 7 min read
By Marc-Andre Tanguay
May 14th, 2020 5 min read
By N‑able
May 13th, 2020 4 min read
By N‑able
May 13th, 2020 6 min read
By Gill Langston
May 13th, 2020 7 min read
By Carrie Reber
May 12th, 2020 4 min read
By N‑able
May 12th, 2020 6 min read
By N‑able
May 11th, 2020 4 min read
By Eric Harless
May 8th, 2020 8 min read
By Eric Anthony
May 7th, 2020 5 min read
By N‑able
May 7th, 2020 5 min read
By N‑able
May 7th, 2020 10 min read
By N‑able
May 6th, 2020 9 min read
By N‑able
May 4th, 2020 6 min read
By N‑able
April 30th, 2020 7 min read
By N‑able
April 29th, 2020 6 min read
By Marc-Andre Tanguay
April 29th, 2020 6 min read
By N‑able
April 28th, 2020 6 min read
By N‑able
April 28th, 2020 9 min read
By N‑able
April 27th, 2020 6 min read
By N‑able
April 23rd, 2020 5 min read
By N‑able
April 22nd, 2020 7 min read
By N‑able
April 21st, 2020 9 min read
By N‑able
April 21st, 2020 6 min read
By N‑able
April 20th, 2020 6 min read
By Marc-Andre Tanguay
April 17th, 2020 7 min read
By Gill Langston
April 15th, 2020 6 min read
By Marc-Andre Tanguay
April 15th, 2020 2 min read
By N‑able
April 14th, 2020 9 min read
By N‑able
April 13th, 2020 8 min read
By Eric Anthony
April 9th, 2020 4 min read
By N‑able
April 7th, 2020 6 min read
By N‑able
April 7th, 2020 7 min read
By N‑able
April 6th, 2020 7 min read
By N‑able
April 6th, 2020 7 min read
By N‑able
April 3rd, 2020 4 min read
By Eric Harless
April 2nd, 2020 13 min read
By N‑able Guest
April 2nd, 2020 5 min read
By Marc-Andre Tanguay
April 1st, 2020 4 min read
By N‑able
March 31st, 2020 6 min read
By Eric Harless
March 31st, 2020 7 min read
By N‑able
March 31st, 2020 9 min read
By N‑able
March 30th, 2020 6 min read
By Mia Thompson
March 26th, 2020 7 min read
By Marc-Andre Tanguay
March 25th, 2020 1 min read
By Gill Langston
March 25th, 2020 5 min read
By Eric Anthony
March 24th, 2020 6 min read
By N‑able
March 24th, 2020 8 min read
By N‑able
March 23rd, 2020 9 min read
By N‑able
March 19th, 2020 6 min read
By N‑able
March 18th, 2020 5 min read
By Marc-Andre Tanguay
March 18th, 2020 5 min read
By N‑able
March 17th, 2020 8 min read
By N‑able
March 17th, 2020 7 min read
By N‑able
March 16th, 2020 8 min read
By Gill Langston
March 13th, 2020 7 min read
By Eric Anthony
March 12th, 2020 5 min read
By Gill Langston
March 11th, 2020 5 min read
By Tim Brown
March 11th, 2020 7 min read
By N‑able
March 10th, 2020 9 min read
By N‑able
March 9th, 2020 7 min read
By N‑able
March 5th, 2020 6 min read
By N‑able
March 5th, 2020 6 min read
By Eric Anthony
March 4th, 2020 5 min read
By N‑able
March 3rd, 2020 5 min read
By N‑able
March 3rd, 2020 5 min read
By Eric Harless
March 3rd, 2020 8 min read
By N‑able
March 2nd, 2020 6 min read
By N‑able
February 27th, 2020 5 min read
By N‑able
February 27th, 2020 6 min read
By Marc-Andre Tanguay
February 26th, 2020 4 min read
By N‑able
February 25th, 2020 9 min read
By N‑able Guest
February 25th, 2020 5 min read
By N‑able
February 25th, 2020 5 min read
By N‑able
February 24th, 2020 7 min read
By N‑able
February 20th, 2020 10 min read
By N‑able
February 20th, 2020 5 min read
By Tim Brown
February 18th, 2020 6 min read
By N‑able
February 18th, 2020 5 min read
By N‑able
February 17th, 2020 11 min read
By N‑able
February 13th, 2020 4 min read
By Eric Anthony
February 13th, 2020 5 min read
By Gill Langston
February 12th, 2020 7 min read
By Marc-Andre Tanguay
February 12th, 2020 4 min read
By N‑able
February 11th, 2020 8 min read
By N‑able
February 10th, 2020 5 min read
By Tim Brown
February 10th, 2020 7 min read
By N‑able
February 10th, 2020 8 min read
By Carrie Reber
February 6th, 2020 3 min read
By N‑able
February 6th, 2020 7 min read
By Tim Brown
February 5th, 2020 6 min read
By N‑able
February 4th, 2020 9 min read
By N‑able
February 4th, 2020 7 min read
By N‑able Guest
February 3rd, 2020 4 min read
By Gill Langston
January 30th, 2020 6 min read
By N‑able
January 30th, 2020 8 min read
By N‑able
January 30th, 2020 5 min read
By Marc-Andre Tanguay
January 29th, 2020 4 min read
By N‑able
January 28th, 2020 5 min read
By N‑able
January 28th, 2020 5 min read
By N‑able
January 27th, 2020 9 min read
By Tim Brown
January 24th, 2020 7 min read
By N‑able
January 24th, 2020 8 min read
By N‑able
January 23rd, 2020 6 min read
By N‑able
January 23rd, 2020 6 min read
By Tim Brown
January 22nd, 2020 8 min read
By N‑able
January 21st, 2020 5 min read
By N‑able
January 20th, 2020 9 min read
By Tim Brown
January 17th, 2020 6 min read
By Eric Anthony
January 16th, 2020 4 min read
By Marc-Andre Tanguay
January 15th, 2020 4 min read
By Gill Langston
January 14th, 2020 3 min read
By N‑able
January 14th, 2020 9 min read
By N‑able
January 13th, 2020 4 min read
By Carrie Reber
January 10th, 2020 3 min read
By Eric Anthony
January 8th, 2020 3 min read
By N‑able
January 7th, 2020 9 min read
By N‑able
January 6th, 2020 8 min read
By Mia Thompson
January 3rd, 2020 6 min read
By Eric Anthony
January 2nd, 2020 4 min read
By N‑able
December 31st, 2019 10 min read
By N‑able
December 30th, 2019 7 min read
By N‑able
December 26th, 2019 8 min read
By N‑able
December 23rd, 2019 5 min read
By N‑able
December 19th, 2019 10 min read
By N‑able
December 18th, 2019 10 min read
By Mia Thompson
December 16th, 2019 6 min read
By N‑able
December 11th, 2019 7 min read
By Eric Anthony
December 5th, 2019 3 min read
By N‑able
December 5th, 2019 5 min read
By N‑able
December 3rd, 2019 6 min read
By N‑able
December 2nd, 2019 7 min read
By Tim Brown
November 29th, 2019 5 min read
By N‑able
November 28th, 2019 6 min read
By N‑able
November 27th, 2019 9 min read
By N‑able
November 26th, 2019 9 min read
By N‑able
November 20th, 2019 5 min read
By N‑able
November 18th, 2019 11 min read
By N‑able
November 15th, 2019 5 min read
By N‑able
November 13th, 2019 7 min read
By N‑able
November 12th, 2019 6 min read
By N‑able
November 12th, 2019 5 min read
By Kim Cecchini
November 7th, 2019 7 min read
By N‑able
November 6th, 2019 11 min read
By N‑able
November 6th, 2019 5 min read
By N‑able
November 4th, 2019 6 min read
By N‑able
October 30th, 2019 10 min read
By N‑able
October 28th, 2019 8 min read
By N‑able
October 24th, 2019 4 min read
By N‑able
October 23rd, 2019 7 min read
By N‑able
October 17th, 2019 10 min read
By N‑able
October 16th, 2019 10 min read
By N‑able
October 10th, 2019 7 min read
By N‑able
October 9th, 2019 7 min read
By N‑able
October 7th, 2019 7 min read
By N‑able Guest
October 3rd, 2019 5 min read
By Eric Anthony
October 2nd, 2019 4 min read
By N‑able
September 30th, 2019 4 min read
By N‑able
September 25th, 2019 10 min read
By Eric Anthony
September 24th, 2019 5 min read
By N‑able
September 23rd, 2019 5 min read
By N‑able
September 18th, 2019 7 min read
By N‑able
September 13th, 2019 7 min read
By N‑able
September 12th, 2019 5 min read
By Marc-Andre Tanguay
September 11th, 2019 3 min read
By N‑able
September 11th, 2019 6 min read
By Eric Anthony
September 10th, 2019 5 min read
By N‑able
September 9th, 2019 8 min read
By Tim Brown
September 5th, 2019 7 min read
By Marc-Andre Tanguay
September 4th, 2019 7 min read
By N‑able
September 4th, 2019 6 min read
By N‑able
September 2nd, 2019 5 min read
By N‑able
August 30th, 2019 4 min read
By N‑able
August 29th, 2019 7 min read
By N‑able
August 27th, 2019 8 min read
By N‑able
August 26th, 2019 9 min read
By N‑able
August 23rd, 2019 3 min read
By Eric Anthony
August 22nd, 2019 4 min read
By N‑able
August 20th, 2019 9 min read
By N‑able
August 19th, 2019 5 min read
By N‑able
August 16th, 2019 6 min read
By N‑able
August 13th, 2019 5 min read
By N‑able
August 12th, 2019 5 min read
By Mia Thompson
August 8th, 2019 4 min read
By N‑able
August 8th, 2019 10 min read
By N‑able
August 6th, 2019 8 min read
By N‑able
August 5th, 2019 8 min read
By N‑able
August 1st, 2019 8 min read
By N‑able
July 29th, 2019 10 min read
By N‑able
July 26th, 2019 9 min read
By N‑able
July 25th, 2019 6 min read
By N‑able
July 24th, 2019 5 min read
By N‑able
July 23rd, 2019 5 min read
By N‑able
July 17th, 2019 7 min read
By Eric Anthony
July 16th, 2019 5 min read
By N‑able
July 15th, 2019 6 min read
By N‑able
July 12th, 2019 4 min read
By N‑able
July 10th, 2019 4 min read
By N‑able
July 10th, 2019 7 min read
By N‑able
July 8th, 2019 6 min read
By N‑able
July 5th, 2019 4 min read
By N‑able
July 3rd, 2019 6 min read
By N‑able
July 3rd, 2019 7 min read
By N‑able
July 1st, 2019 7 min read
By N‑able
June 28th, 2019 8 min read
By N‑able
June 26th, 2019 5 min read
By Carrie Reber
June 25th, 2019 2 min read
By Carrie Reber
June 21st, 2019 3 min read
By N‑able
June 20th, 2019 6 min read
By Mia Thompson
June 13th, 2019 4 min read
By N‑able
June 10th, 2019 8 min read
By N‑able
June 7th, 2019 7 min read
By N‑able
June 3rd, 2019 12 min read
By Tim Brown
May 21st, 2019 5 min read
By N‑able
May 19th, 2019 8 min read
By N‑able
May 10th, 2019 13 min read
By N‑able
May 9th, 2019 8 min read
By N‑able
May 7th, 2019 6 min read
By N‑able
May 7th, 2019 1 min read
By N‑able
May 6th, 2019 5 min read
By Tim Brown
May 1st, 2019 5 min read
By N‑able
April 26th, 2019 5 min read
By N‑able
April 24th, 2019 12 min read
By N‑able
April 23rd, 2019 10 min read
By N‑able
April 22nd, 2019 8 min read
By N‑able
April 22nd, 2019 11 min read
By N‑able
April 21st, 2019 15 min read
By N‑able
April 18th, 2019 10 min read
By N‑able
April 17th, 2019 10 min read
By N‑able
April 15th, 2019 8 min read
By N‑able
April 12th, 2019 9 min read
By N‑able
April 12th, 2019 8 min read
By N‑able
April 11th, 2019 10 min read
By N‑able
April 10th, 2019 7 min read
By N‑able
April 5th, 2019 6 min read
By N‑able
April 4th, 2019 6 min read
By N‑able
April 2nd, 2019 8 min read
By N‑able
April 1st, 2019 9 min read
By N‑able Guest
March 29th, 2019 5 min read
By N‑able
March 28th, 2019 10 min read
By N‑able
March 27th, 2019 10 min read
By N‑able
March 26th, 2019 7 min read
By N‑able
March 25th, 2019 7 min read
By N‑able
March 22nd, 2019 6 min read
By Mia Thompson
March 21st, 2019 8 min read
By Eric Anthony
March 20th, 2019 4 min read
By Tim Brown
March 18th, 2019 6 min read
By N‑able
March 13th, 2019 8 min read
By N‑able
March 12th, 2019 8 min read
By N‑able
March 8th, 2019 6 min read
By N‑able
March 6th, 2019 6 min read
By N‑able
March 4th, 2019 9 min read
By N‑able
March 1st, 2019 13 min read
By Tim Brown
February 27th, 2019 7 min read
By N‑able
February 26th, 2019 11 min read
By N‑able
February 25th, 2019 8 min read
By N‑able
February 21st, 2019 7 min read
By N‑able
February 20th, 2019 6 min read
By N‑able
February 18th, 2019 7 min read
By Mia Thompson
February 15th, 2019 5 min read
By Eric Anthony
February 14th, 2019 4 min read
By N‑able
February 1st, 2019 4 min read
By N‑able
January 17th, 2019 8 min read
By Eric Anthony
January 15th, 2019 5 min read
By N‑able
January 8th, 2019 4 min read
By N‑able
January 4th, 2019 7 min read
By Carrie Reber
December 24th, 2018 3 min read
By N‑able
December 13th, 2018 6 min read
By Eric Anthony
December 11th, 2018 6 min read
By N‑able
December 5th, 2018 7 min read
By Danny Bradbury
December 3rd, 2018 11 min read
By N‑able
November 30th, 2018 5 min read
By N‑able
November 9th, 2018 5 min read
By N‑able
October 23rd, 2018 5 min read
By Eric Anthony
October 11th, 2018 7 min read
By N‑able
October 4th, 2018 5 min read
By Carrie Reber
September 4th, 2018 6 min read
By Danny Bradbury
August 31st, 2018 5 min read
By N‑able
August 25th, 2018 5 min read
By N‑able Guest
August 17th, 2018 5 min read
By Eric Anthony
August 16th, 2018 5 min read
By N‑able Guest
August 15th, 2018 5 min read
By N‑able Guest
August 9th, 2018 6 min read
By Pete Roythorne
August 7th, 2018 4 min read
By Eric Anthony
August 2nd, 2018 4 min read
By N‑able Guest
July 31st, 2018 6 min read
By Carrie Reber
July 12th, 2018 5 min read
By N‑able
July 11th, 2018 4 min read
By Tim Brown
July 3rd, 2018 5 min read
By Sebastian Antonescu
June 26th, 2018 4 min read
By N‑able Guest
June 22nd, 2018 5 min read
By Eric Anthony
June 19th, 2018 3 min read
By Sebastian Antonescu
June 12th, 2018 6 min read
By N‑able
June 6th, 2018 5 min read
By N‑able
June 5th, 2018 5 min read
By N‑able Guest
June 1st, 2018 4 min read
By Kevin Kirkpatrick
May 29th, 2018 4 min read
By N‑able Guest
May 11th, 2018 4 min read
By Tim Brown
May 10th, 2018 5 min read
By N‑able Guest
May 8th, 2018 5 min read
By Eric Anthony
May 2nd, 2018 8 min read
By N‑able
April 27th, 2018 8 min read
By N‑able
April 26th, 2018 5 min read
By N‑able Guest
April 17th, 2018 7 min read
By Tim Brown
April 10th, 2018 6 min read
By Tim Brown
April 5th, 2018 5 min read
By Kevin Kirkpatrick
March 29th, 2018 5 min read
By Eric Anthony
March 28th, 2018 4 min read
By Eric Anthony
March 22nd, 2018 6 min read
By Tony Meyer
March 20th, 2018 6 min read
By N‑able
March 9th, 2018 4 min read
By Kevin Kirkpatrick
March 1st, 2018 4 min read
By Eric Anthony
February 27th, 2018 6 min read
By N‑able
February 23rd, 2018 5 min read
By N‑able
February 21st, 2018 7 min read
By N‑able
February 13th, 2018 5 min read
By N‑able
February 8th, 2018 3 min read
By N‑able Guest
February 2nd, 2018 4 min read
By Eric Anthony
January 30th, 2018 5 min read
By N‑able
January 15th, 2018 9 min read
By N‑able
January 8th, 2018 3 min read
By N‑able
January 4th, 2018 6 min read
By Nick Cavalancia
December 27th, 2017 5 min read
By N‑able Guest
December 21st, 2017 6 min read
By Eric Anthony
December 12th, 2017 6 min read
By N‑able
December 7th, 2017 4 min read
By Dan Toth
November 30th, 2017 8 min read
By N‑able Guest
November 28th, 2017 4 min read
By N‑able Guest
November 10th, 2017 7 min read
By N‑able
November 9th, 2017 7 min read
By N‑able Guest
October 30th, 2017 4 min read
By Nick Cavalancia
October 29th, 2017 4 min read
By N‑able Guest
October 27th, 2017 4 min read
By N‑able
October 17th, 2017 5 min read
By N‑able Guest
October 12th, 2017 8 min read
By N‑able Guest
October 5th, 2017 5 min read
By N‑able
October 3rd, 2017 4 min read
By Nick Cavalancia
September 28th, 2017 6 min read
By N‑able
September 26th, 2017 5 min read
By N‑able
September 15th, 2017 4 min read
By N‑able Guest
August 29th, 2017 5 min read
By Pete Roythorne
August 16th, 2017 4 min read
By N‑able Guest
August 15th, 2017 7 min read
By Eric Anthony
August 3rd, 2017 4 min read
By N‑able Guest
August 1st, 2017 6 min read
By N‑able Guest
July 27th, 2017 6 min read
By N‑able
July 18th, 2017 6 min read
By Danny Bradbury
July 13th, 2017 6 min read
By N‑able
June 28th, 2017 4 min read
By N‑able
June 22nd, 2017 8 min read
By N‑able Guest
June 20th, 2017 7 min read
By N‑able Guest
June 15th, 2017 9 min read
By N‑able Guest
June 1st, 2017 5 min read
By N‑able Guest
May 30th, 2017 6 min read
By N‑able Guest
May 18th, 2017 7 min read
By N‑able
May 17th, 2017 6 min read
By N‑able
May 16th, 2017 6 min read
By N‑able Guest
May 5th, 2017 5 min read
By N‑able Guest
April 25th, 2017 6 min read
By N‑able
April 20th, 2017 12 min read
By N‑able
April 13th, 2017 7 min read
By Pete Roythorne
April 12th, 2017 4 min read
By Danny Bradbury
April 11th, 2017 4 min read
By N‑able Guest
April 7th, 2017 4 min read
By Dan O'Keefe
March 30th, 2017 11 min read
By Nick Cavalancia
March 29th, 2017 22 min read
By Danny Bradbury
March 17th, 2017 20 min read
By Dan O'Keefe
February 25th, 2017 7 min read
By N‑able
February 24th, 2017 5 min read
By N‑able
February 7th, 2017 4 min read
By Ian Waters
January 24th, 2017 8 min read
By N‑able
January 11th, 2017 5 min read
By N‑able
January 3rd, 2017 5 min read
By Karl Palachuk
December 23rd, 2016 8 min read
By N‑able Guest
December 19th, 2016 6 min read
By Dan O'Keefe
December 14th, 2016 3 min read
By N‑able
December 8th, 2016 3 min read
By Dan O'Keefe
December 2nd, 2016 3 min read
By N‑able
November 30th, 2016 3 min read
By N‑able
November 29th, 2016 4 min read
By N‑able
November 24th, 2016 4 min read
By Dan O'Keefe
November 22nd, 2016 3 min read
By Pete Roythorne
November 17th, 2016 3 min read
By N‑able Guest
November 16th, 2016 4 min read
By N‑able
November 10th, 2016 5 min read
By N‑able Guest
November 8th, 2016 3 min read
By N‑able
November 2nd, 2016 4 min read
By N‑able
November 1st, 2016 2 min read
By N‑able
October 19th, 2016 10 min read
By Eric Anthony
October 13th, 2016 5 min read
By Nick Cavalancia
October 12th, 2016 4 min read
By N‑able
October 5th, 2016 5 min read
By Karl Palachuk
October 4th, 2016 8 min read
By Karl Palachuk
September 20th, 2016 9 min read
By Karl Palachuk
September 13th, 2016 5 min read
By Karl Palachuk
September 8th, 2016 6 min read
By N‑able Guest
September 6th, 2016 6 min read
By Dan O'Keefe
August 24th, 2016 5 min read
By N‑able
August 17th, 2016 5 min read
By N‑able Guest
August 9th, 2016 7 min read
By N‑able
August 9th, 2016 4 min read
By Danny Bradbury
August 4th, 2016 5 min read
By Karl Palachuk
July 26th, 2016 5 min read
By N‑able
July 21st, 2016 5 min read
By David Lanetta
July 15th, 2016 4 min read
By Karl Palachuk
July 12th, 2016 9 min read
By N‑able
July 3rd, 2016 3 min read
By N‑able
June 29th, 2016 6 min read
By Karl Palachuk
June 28th, 2016 8 min read
By Eric Anthony
June 22nd, 2016 4 min read
By Danny Bradbury
June 16th, 2016 4 min read
By N‑able Guest
June 14th, 2016 9 min read
By Karl Palachuk
June 7th, 2016 6 min read
By N‑able
May 25th, 2016 5 min read
By Karl Palachuk
May 24th, 2016 8 min read
By N‑able
May 18th, 2016 6 min read
By N‑able Guest
May 16th, 2016 7 min read
By N‑able
May 11th, 2016 5 min read
By Karl Palachuk
May 9th, 2016 8 min read
By N‑able Guest
May 6th, 2016 5 min read
By N‑able
May 6th, 2016 4 min read
By N‑able
May 6th, 2016 7 min read
By N‑able Guest
April 19th, 2016 10 min read
By Nick Cavalancia
April 14th, 2016 6 min read
By Nick Cavalancia
April 7th, 2016 4 min read
By Pete Roythorne
April 5th, 2016 4 min read
By N‑able Guest
March 31st, 2016 10 min read
By N‑able Guest
March 22nd, 2016 6 min read
By Nick Cavalancia
March 17th, 2016 3 min read
By Karl Palachuk
February 24th, 2016 10 min read
By Karl Palachuk
February 10th, 2016 6 min read
By Karl Palachuk
February 4th, 2016 8 min read
By N‑able
February 3rd, 2016 5 min read
By Karl Palachuk
December 8th, 2015 6 min read
By Nick Cavalancia
December 3rd, 2015 3 min read
By N‑able
November 17th, 2015 4 min read
By N‑able
November 12th, 2015 4 min read
By Nick Cavalancia
November 3rd, 2015 5 min read
By N‑able
October 21st, 2015 7 min read
By N‑able
October 16th, 2015 2 min read
By N‑able
September 17th, 2015 7 min read
By Nick Cavalancia
September 17th, 2015 1 min read
By N‑able
August 13th, 2015 4 min read
By N‑able
August 10th, 2015 8 min read
By N‑able Guest
June 19th, 2015 5 min read
By N‑able
June 8th, 2015 4 min read
By N‑able
May 26th, 2015 4 min read
By N‑able
May 18th, 2015 2 min read
By N‑able
May 12th, 2015 4 min read
By N‑able
May 8th, 2015 9 min read
By N‑able
May 1st, 2015 5 min read
By David Lanetta
April 24th, 2015 6 min read
By N‑able
April 9th, 2015 6 min read
By N‑able
April 9th, 2015 3 min read
By N‑able
April 7th, 2015 5 min read
By N‑able
March 31st, 2015 5 min read
By N‑able
March 20th, 2015 7 min read
By David Lanetta
March 20th, 2015 6 min read
By N‑able
March 9th, 2015 4 min read
By N‑able Guest
February 25th, 2015 4 min read
By N‑able Guest
February 12th, 2015 6 min read
By Nick Cavalancia
January 13th, 2015 5 min read
By Karl Palachuk
December 29th, 2014 9 min read
By N‑able
December 11th, 2014 4 min read
By N‑able
December 4th, 2014 4 min read
By Nick Cavalancia
November 21st, 2014 5 min read
By N‑able
November 19th, 2014 6 min read
By N‑able
November 11th, 2014 3 min read
By N‑able
November 11th, 2014 4 min read
By N‑able
November 11th, 2014 8 min read
By N‑able
November 10th, 2014 3 min read
By Nick Cavalancia
October 28th, 2014 4 min read
By N‑able Guest
October 17th, 2014 3 min read
By N‑able
August 29th, 2014 4 min read
By Nick Cavalancia
August 28th, 2014 5 min read
By N‑able
August 1st, 2014 3 min read
By N‑able
July 23rd, 2014 5 min read
By N‑able Guest
July 7th, 2014 5 min read
By Nick Cavalancia
June 24th, 2014 4 min read
By N‑able Guest
May 14th, 2014 5 min read
By N‑able
April 8th, 2014 5 min read
By N‑able
April 2nd, 2014 3 min read
By N‑able
March 24th, 2014 3 min read
By N‑able
March 21st, 2014 3 min read
By N‑able
March 3rd, 2014 3 min read
By N‑able
February 26th, 2014 3 min read
By N‑able
February 14th, 2014 4 min read
By N‑able Guest
February 12th, 2014 5 min read
By N‑able Guest
February 11th, 2014 4 min read
By N‑able
January 13th, 2014 4 min read
By N‑able
November 8th, 2013 3 min read
By N‑able
September 27th, 2013 3 min read
By N‑able Guest
September 13th, 2013 7 min read
By N‑able
September 6th, 2013 3 min read
By N‑able
September 4th, 2013 4 min read
By N‑able
August 12th, 2013 3 min read
By N‑able
August 5th, 2013 7 min read
By Scott Calonico
July 1st, 2013 4 min read
By Scott Calonico
June 24th, 2013 4 min read
By N‑able Guest
May 20th, 2013 6 min read
By N‑able
March 25th, 2013 5 min read
By N‑able
February 19th, 2013 6 min read
By Todd Haugland
February 17th, 2013 8 min read
By N‑able
January 31st, 2013 3 min read
By N‑able Guest
January 28th, 2013 6 min read
By N‑able
October 9th, 2012 3 min read
By Scott Calonico
September 25th, 2012 4 min read
By N‑able Guest
August 16th, 2012 3 min read
By N‑able
August 7th, 2012 3 min read
By Scott Calonico
July 17th, 2012 4 min read
By N‑able Guest
April 12th, 2012 6 min read
By N‑able Guest
March 27th, 2012 5 min read
By N‑able
March 20th, 2012 7 min read
By N‑able
March 13th, 2012 5 min read
By N‑able
November 28th, 2011 4 min read
By N‑able Guest
October 6th, 2011 5 min read
By N‑able Guest
August 29th, 2011 4 min read
By N‑able
August 16th, 2011 7 min read
By N‑able
August 12th, 2011 6 min read
By N‑able
July 18th, 2011 4 min read
By Scott Calonico
July 12th, 2011 4 min read
By N‑able
June 7th, 2011 5 min read
By N‑able
May 21st, 2011 5 min read
By N‑able
April 21st, 2011 3 min read
By N‑able
April 20th, 2011 2 min read
By N‑able Guest
March 7th, 2011 4 min read